Опыт построения DPI IP/ECMP based фабрики на оборудовании Juniper QFX10k с применением symmetric hashing
15 Jul 2021 - somovis
Share on:В данной заметке я хочу поделится опытом построения DPI блока сети передачи данных (PoD) на оборудовании Juniper QFX10k являющегося частью EVPN/VXLAN фабрики с применением IP/ECMP, symmetric hashing, resilient hashing.
Дисклеймер
В дальнейшем любые совпадения в названии производителей носят случайный характер :)
Определения
- DPI - Deep Packet Inspection или глубокий анализ пакетов;
- IPS - Intrusion Prevention System или система предотвращения вторжений;
- ECMP - Equal-Cost Multi-Path;
- HA - High Availability или высокая доступность;
- scale-up - наращивание емкости увеличением производительности устройств(а);
- scale-out - наращивание емкости увеличением количества устройств той же или аналогичной производительности;
- fw - firewall, в нашем случае это и есть DPI устройство;
- leaf/spine - физические роли устройств в CLOS based IP фабрике;
- tfs - transit fabric switch;
- edge - пограничное устройство для конкретного сегмента сети;
- p - MPLS LSR.
Вступление
Мотивацией для написания данной заметки стало тотальное отсутствие в русскоязычном сегменте подобного материала, надеюсь, что моя заметка кому-нибудь поможет в дальнейшем.
Порой встречаются довольно интересные задачи, вот так и мне однажды посчастливилось, когда нам понадобилось построить для защиты определенного сегмента сети DPI блок СПД с применением IPS. Не буду вдаваться в подробности на этом моменте, нас же больше интересует техническое решение задачи.
Вот так выглядит целевая схема DPI блока СПД:
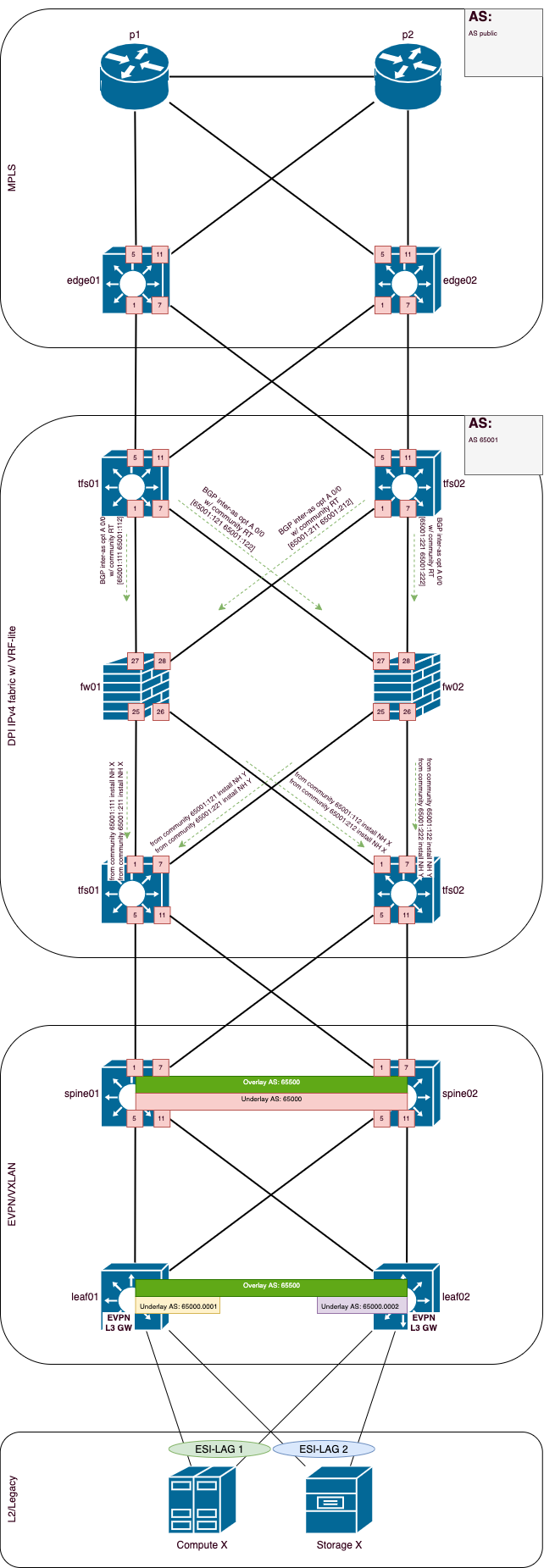
Целевая схема в PDF
Если ты, уважаемый читатель, сразу ее понял и во всем разобрался, то можешь далее не читать. Но если у тебя остались еще вопросы, то милости прошу под кат.
Коротко опишу данную схему СПД:
- p устройства - это выделенные LSR (да, у нас собственный выделенный backbone);
- edge устройства - это MPLS PE, в котором осуществляется прием префиксов в различных VPN со стороны backbone и в каждом VPN выполняется агрегация префиксов до
0/0, и0/0отправляется на tfs по BGP в AF IPv4 (inter-as option A); - tfs устройства - это транзитные L3 коммутаторы, на которых есть возможность сделать симметричную балансировку по ECMP и есть функционал vrf-lite/virtual router (или аналогичные механизмы разделения RIB) и/или EVPN/VXLAN с поддержкой route type 5. Они принимают по BGP
0/0префикс от edge и отправляют этот префикс на fw, так же, по BGP. Аналогично, в противоположном направлении полученные специфики от spine отправляются на fw; - fw устройства - это МСЭ с функционалом DPI и IPS, также они являются транзитными маршрутизаторами и принимают по BGP
0/0префикс от tfs со стороны edge, и отправляют этот префикс на tfs, в сторону spine, так же, по BGP. Аналогично, в противоположном направлении полученные специфики от tfs со стороны spine отправляются на tfs в сторону edge; - spine устройства - в нашем случае это совмещение ролей spine и border leaf, потому-что потребовалось сэкономить и схема маршрутизации ERB, но, BGP IPv4 сессия с tfs терминируется на spine в конкретном VPN (inter-AS option A), и полученный от fw
0/0префикс экспортируется в EVPN как route type 5 префикс, чтобы достичь leaf коммутаторов; - leaf - это коммутаторы доступа в ДЦ, на которых выполняется маршрутизация внутри и между стойками, потому-что используется именно ERB схема маршрутизации, кроме того, в требуемых VPN leaf экспортируют конкретные префиксы конкретных VPN в EVPN как route type 5 префиксы, и отправляют на spine, а spine в свою очередь отправляют их на tfs по BGP в AF IPv4 (inter-as option A) и так далее.
Хочу обратить внимание, что данное техническое решение прорабатывалось в начале 2020 года, а схема тестировалась на разных платформах и моделях разных производителей, но сейчас уже появилось более дешевое/новое оборудование или обновление ПО для более дешевого оборудования того же производителя, которое тоже подходит для решения данной задачи, при этом, некоторое протестированное оборудование уже может быть недоступно для заказа.
ТЗ было примерно следующим:
- Инспектировать ~500Гбит трафика при помощи IPS;
- Отказоустойчивость DPI блока СПД;
- Inline DPI;
- Сертифицированное ФСТЭК оборудование;
- Потенциальный рост - проработать масштабирование;
- Универсальный дизайн DPI блока СПД для потенциальной возможности применения различного оборудования DPI при масштабировании - все же конкурентные закупки;
- Сделать дешевле, с учетом роста трафика и последующих апгрейдов.
Размышления
Если говорить про техническое решение и посмотреть в корень задачи, то можно увидеть, что требуется IPS на ~500Гбит, резервирование и потенциальный рост.
При этом, исходя из своего опыта, общения с коллегами и производителями, могу сказать, что для решения данной задачи не так уж много производителей подходит. Я не буду их перечислять, но хочу акцентировать внимание на проблему, почему так важно, что используется IPS и почему бы не сделать большой кластер или не поставить два устройства размером с шкаф:
- У производителя X можно собрать кластер до 16 устройств, но, при этом, трафик предназначенный IPS движку обрабатывает только одно устройство в кластере;
- У производителя Y можно собрать кластер до 16 устройств, но, при этом, результат работы IPS движка не синхронизируется между устройствами в кластере и в зависимости от платформы получаем либо потерю трафика, либо пропуск трафика (зачем тогда вообще IPS?!);
- У производителя Z можно собрать кластер до 2 устройств, но, при этом, результат работы IPS движка синхронизируется, однако, максимальная производительность одного такого устройства на IPS составляет ~800Гбит и имеет довольно высокую цену для покупки сразу обоих устройств в комплектации с целью на ~500Гбит (помним про резервирование).
Поэтому, недолго думая, я предложил использовать 3 сетевых технологии, которые будут ключевыми для решения данной задачи:
- IP/ECMP - в сравнении с MC-LAG позволяет сэкономить количество интерфейсов (убираем ICL, QSFP28 стоят денег), отсутствие L2 и slow protocols, наличие гибкого управления трафиком, горизонтальное масштабирование;
- Symmetric hashing - для управления прохождением трафика в оба направления через одно и то же DPI устройство;
- Resilient hashing - для предотвращения перебалансировки всего трафика при аварии одного (или более) DPI устройства.
Рекомендую ознакомиться с данными технологиями перед дальнейшим прочтением материала.
Отсутствие кластеризации со стороны DPI устройств нам не повредит, но естественно будут особенности, подробнее в секции Проблемы.
Спустя какое-то время, занимаясь тестированием DPI платформ, мы увидели оптимальное для данной задачи решение в рамках одного устройства:
- Инспектировать ~130Гбит трафика при помощи IPS - мало ли потребуется добавить в IPS еще какие-то паттерны;
- 4*100G интерфейса;
- Поддержка остального требуемого функционала. В следствии чего, мы закрепили наш выбор, что масштабирование будет горизонтальным, чтобы достичь требуемой емкости, а резервирование DPI устройств будет N+1. Этого будет достаточно для абсорбирования возможных всплесков трафика или при ожидании поставки оборудования для требуемого расширения емкости. Конечно, в этом случае мы можем потерять резервирование, поэтому, в идеале, резервирование должно быть N+2, но реальный мир суров и не все, и не всегда, можно сделать так, как хочешь именно ты.
Высокая доступность
Прежде чем говорить о масштабировании, следует упомянуть высокую доступность, у данного термина есть следующее определение: “свойство системы быть защищённой и легко восстанавливаемой от небольших простоев в короткое время автоматизированными средствами.”. Не стоит путать данный термин с надежностью.
В мире телекоммуникаций высокая доступность достигается резервированием [1, 2] тех или иных компонентов. Есть следующие виды резервирования:
- Холодный (ненагруженный) резерв - данный термин очень хорошо определяет известная в телеком сообществе шутка: “чтобы зарезервировать один микротик, нужно 3 микротика - один рядом с уже работающим и один в шкафу, пока третий на доставке.”. Вот холодный резерв как раз про микротик в шкафу. Но если без шуток, то вот определение: “резервные элементы не несут нагрузки или выключены и ожидают включения.”;
- Горячий (нагруженный) резерв - как ты понял, это про второй микротик, рядом с уже работающим, но не совсем. Вот четкое определение: “резервные элементы нагружены так же, как и основные.”.;
- Теплый (облегченный) резерв - В данном случае второй микротик может им быть, но может и не быть. Определение: “резервные элементы нагружены меньше, чем основные.”;
- Резервирование замещением - резервирование, при котором функции основного элемента передаются резервному только после отказа основного элемента. Резервирование замещением может быть с холодным, теплым или горячим резервом. Его недостатком является зависимость от надежности переключающих устройств.
Не привычно, правда? Мы ведь давно привыкли, что:
- Холодный резерв - это ЗИП или резервирование замещением;
- Горячий резерв делится на подтипы:
- active/standby - один или более элементов не активны и ожидают;
- active/active - все элементы активны.
- А теплый резерв и в помине не упоминается.
Но есть ГОСТ, МЭК и прочие, в которых даются четкие определения.
Ладно, вернемся к миру телекоммуникаций и пропустим все виды резервирования, кроме привычных нам a/s, a/a.
active/standby
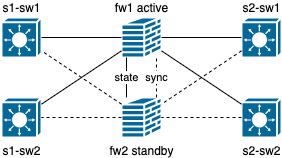
Классический вариант, используемый в большинстве корпоративных сетей, начиная от STP (да, его можно использовать не только как защиту от петель), резервирования шлюза средствами VRRP/HSRP и заканчивая резервированием устройства предоставляющее сервис.
Ни для кого не секрет, что в данном виде резервирования часть устройств ждет аварии/переключения, чтобы перейти из режима ожидания в активный режим.
В данном виде резервирования, как правило, используется группа из двух устройств (Cluster/MC-LAG) и этот вид резервирования больше подходит для scale-up масштабирования, потому-что других вариантов внутри группы из двух устройств попросту нет.
Плюсы:
- Меньше точек входа;
- Проще поиск и устранение неисправностей;
- Резервное оборудование готово перехватить нагрузку и в 99% случаев справится с ней.
Минусы:
- Резервное оборудование в большинстве случаев простаивает и вообще не используется (не подходит операторским сетям);
- Во время аварийного переключения резерва может встретится этот самый 1%, когда оборудование не справляется с нагрузкой или с ним возникают еще какие-либо проблемы. Все это из-за того, что не происходит периодическое тестирование резерва и его переключения.
active/active
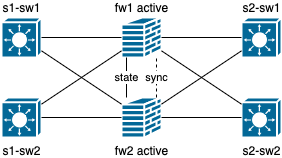
А этот вид резервирования уже более интересен инженерам и операторским сетям, так как нагрузка распределяется между всеми устройствами в группе устройств (Cluster/MC-LAG/GLBP), но нельзя сказать, что всегда распределяется равномерно, особенно если это касается гео-распределенных кластеров (не нужно так, пожалуйста, берегите нервы себе и своим инженерам!).
Плюсы:
- Распределение нагрузки по группе устройств.
Минусы:
- Больше точек входа (стоит задуматься про автоматизацию);
- Сложнее поиск и устранение неисправностей;
- В случае с IPS, требуется синхронизация результата работы IPS движка, иначе могут быть негативные последствия;
- Требуется всегда следить за нагрузкой устройств. Если резервирование 1+1, то рекомендую нагружать устройства не более 40-45%, чтобы в случае аварии, оставшееся устройство могло справится с взвалившейся на него нагрузкой. Если говорить про более сложные конструкции, то аналогично можно составить формулу и посчитать момент предельной нагрузки, но это все сильно индивидуально и следует так же уточнить наличие переподписки и ее уровень, и от одиночного или множественных отказов защищаемся.
Масштабирование
Если говорить про выбор того или иного решения, то это всегда компромиссы, поэтому, ниже я опишу различные варианты масштабирования, а также их плюсы и минусы, примеряя их на нашу задачу.
Заядлый инжиниринг
Это, пожалуй, самый не продуктивный и не масштабируемый способ с довольно затратным обслуживанием.
Приведу простой пример: когда-то давно, когда еще не было EVPN (за исключением проприетарного GLBP), когда нужно было зарезервировать шлюз сети, требовалось использовать VRRP/HSRP на группе маршрутизаторов, при этом, только один из маршрутизаторов в данной сети мог быть активным для передачи трафика в направлении из данной сети (исключаем задачу с растянутым VLAN между разными площадками, активным VRRP на каждой площадке и фильтрации VRRP mcast/unicast между площадками). Поэтому, еще тогда придумали псевдо active/active, назначая активными разные маршрутизаторы для разных VLAN (точнее, разные приоритеты для разных VRRP Groups на разных маршрутизаторах), таким образом трафик из VLAN X шел в маршрутизатор 1, а трафик из VLAN Y шел в маршрутизатор 2, и так далее.
Если же мы говорим про управление трафиком между разными сегментами СПД, то это потребует дополнительных маркеров, по которым потом потребуется работать всю жизнь, а не единоразово их применить на сети и забыть навсегда. К тому же, со временем, при масштабировании, придется вносить изменения в маркировку и это вызовет перебалансировку трафика. Не говоря про сложность данного решения в автоматическом режиме, человеку, который только увидит документацию/конфигурацию, будет крайне не просто искать и исправлять потенциально возникшую проблему. В нашем случае мы имеем >100k активных SRC IP-адресов, разбросанных по всей сети (примерно ~10k префиксов) и им всем нужен доступ до сегмента, который мы защищаем. Поэтому, сказать какие маркеры применить на префикс, сколько полосы по факту будут утилизировать SRC IP-адреса за конкретным префиксом и сколько IP-адресов из префикса активно, и сколько будет активно завтра - практически невозможно, а сложность решения ты поймешь далее. В итоге мы отказались от данной опции.
scale-up
Еще одна опция из прошлого, когда практически любая корпоративная и телекоммуникационная компания для увеличения емкости тех или иных ресурсов, просто покупала бОльший компонент, будь то шасси маршрутизатора, коммутационная фабрика маршрутизатора, линейная карта маршрутизатора или целиком само устройство. Да, это применимо к любой системе, не только к маршрутизатору.
Конечно, у данного решения есть свои плюсы:
- Меньше точек входа - настраивается одно устройство, вместо 8;
- Если сегодня использовали 2/8 слотов, а расширение предстоит через пару лет, то можно потом докупить линейные/сервисные/коммутационные карты и установить в свободные слоты;
- Как правило, потребляет меньше электроэнергии, если сравнивать одно модульное устройство в максимальной комплектации с количеством не модульных устройств, которые могут обеспечить паритет по количеству интерфейсов, масштабированию и функционалу;
- Как правило, меньше в размере, если сравнивать одно модульное устройство в максимальной комплектации с количеством не модульных устройств, которые могут обеспечить паритет по количеству интерфейсов, масштабированию и функционалу;
- Проще обновление ПО, так как модули управления обычно зарезервированы, но с ISSU всегда есть риск и повышается вес SPOF;
- В некоторых случаях один сервисный контракт покрывает все компоненты модульного устройства.
Но есть и минусы:
- SPOF - одна точка отказа для всех компонентов (как говорится: “чем больше шкаф - тем громче падает!”);
- Если нужно всего 2/8 слотов, то занимает больше места, чем количество не модульных устройств, которые могут обеспечить паритет по количеству интерфейсов, масштабированию и функционалу;
- Если нужно всего 2/8 слотов, то потребляет больше электроэнергии, чем количество не модульных устройств, которые могут обеспечить паритет по количеству интерфейсов, масштабированию и функционалу;
- Сложнее поиск и исправление неисправностей из-за архитектуры модульного устройства, так как она больше похожа на дизайн CLOS сетей, но может и отличаться от другого модульного устройства, даже в рамках одного производителя;
- Сложнее обновление, вплоть до полной замены устройства, что стоит дорого и может вызвать отказ в обслуживании сервисов;
- Привязка к одному производителю при обновлении - отсутствие конкуренции, потенциально выше стоимость и выше вес SPOF.
scale-out

Горизонтальное масштабирование стало стандартом во многих отраслях за последние 10 лет, будь то масштабирование СПД, приложения или промышленного производства.
Плюсы:
- Меньше SPOF, так как производитель/платформа/модель/компоненты могут отличаться;
- Если нужно небольшое количество устройств, то занимает меньше места, чем модульное устройство, которое может обеспечить паритет по количеству интерфейсов, масштабированию и функционалу;
- Если нужно небольшое количество устройств, то потребляет меньше электроэнергии, чем модульное устройство, которое может обеспечить паритет по количеству интерфейсов, масштабированию и функционалу;
- Проще поиск и исправление неисправностей, так как архитектура одночипового коммутатора в разы проще, чем архитектура модульного устройства;
- Безопаснее обновление ПО, так как устройства независимы и могут резервировать друг друга;
- Проще добавление новых устройств, когда потребуется масштабирование, так как в большинстве случаев просто добавь еще N устройств;
- Возможность использовать разных производителей и разных компонентов - привнесение конкуренции, потенциально ниже стоимость и меньше вес SPOF.
Минусы:
- Больше точек входа - настраивается 8 устройств, вместо одного (но кого это испугает в эпоху автоматизации?!);
- Сложнее целевой дизайн, так как используется бОльшее количество технологий;
- Так как используется бОльшее количество технологий, то увеличивается вероятность отказа, так как потенциально в каждой технологии может быть ошибка (код пишут люди, а люди совершают ошибки).
Cluster

А вот и всеми любимые кластеры, наконец-то!
Но не спешу радовать, мы будем говорить про кластеры в контексте DPI.
Кластер можно частично отнести к дизайну scale-out, так как позволяет масштабировать уже рабочий кластер добавляя в него устройства. Но, каждый кластер лимитирован тем или иным ограничением, включая количество устройств и жестко привязывается к конкретному производителю, а иногда и к платформе/модели устройства, поэтому, исчерпав ресурсы кластера, понадобится строить рядом еще один (чем-то похоже на дизайн PoD, когда, исчерпав ресурсы, строится рядом еще один).
Из плюсов сюда можно отнести следующее:
- Централизованное управление и мониторинг (но не всегда и не везде);
- Синхронизацию состояний потоков;
- Синхронизацию конфигураций устройств (это точно очень нужно ли в эпоху автоматизации?!)
Конечно, кластер имеет свои существенные недостатки, например:
- Наш любимый SPOF;
- Отсутствие синхронизации результата работы IPS движка у большинства известных производителей;
- Другие недостатки, о которых я писал в секции
Размышления, в начале данной заметки.
Для решения текущей задачи данный вариант нам не подошел, но, не исключено, что для другой задачи он подойдет. Хотя, после решения данной задачи, задаешься вопросом: “зачем?!”.
Все последующие варианты будут связаны с symmetric load balancing и resilient/consistent hashing, поэтому, если ты еще по какой-то причине не знаком с ними, то настоятельно рекомендую сперва ознакомится и только потом продолжать чтение данного материала.
MC-LAG L2 Transparent
Один из самых простых и часто встречающихся вариантов. В данном варианте хорошо практически все - MC-LAG пара обеспечивает резервирование коммутаторов/маршрутизаторов, fw работают в прозрачном режиме, но есть один основной момент - если мы используем symmetric hashing и при этом происходит авария на любом линке к fw (например: между spine01 и fw01), то автоматически мы получаем асимметрию. Чтобы избежать данной проблемы, можно использовать детектирование аварии по линку на стороне fw и принудительно выключать зеркальный интерфейс (в данном примере это будет интерфейс между fw01 и edge01). Грубо, жестко, но позволит избежать асимметрии, однако, данный вариант уносит логику на fw и требует поддержки данной возможности на их стороне. Можно, конечно, еще красить пакеты и по DSCP значению принимать решение, но этот подход не будет масштабироваться.
Плюсы:
- Простая логика, если не требуется субсекундное схождение сети;
- Обкатан многими производителями, что уменьшает вероятность встретить ошибку в ПО;
- Минимум затрат и быстрый запуск.
Минусы:
- Отсутствие горизонтального масштабирования из-за MC-LAG - больше двух устройств в группе быть не может (однако, можно построить рядом аналогичную схему);
- Логика по предотвращению асимметрии ложится на fw, что нам тоже не понравилось. К тому-же, стоит помнить, что при масштабировании могут приехать fw другого производителя или модели (конечно, в этом варианте было бы идеально построить рядом еще один PoD на другом производителе, но мир не идеален, ага);
- MC-LAG - это тоже SPOF;
- Если требуется субсекундное схождение сети, то сперва требуется обеспечить высокую скорость (~300ms) детектирования аварии - связано с fw:
- EEM/скрипты сами по себе не быстро отрабатывают (CPU);
- Для OAM LFM требуется поддержка на аппаратном уровне;
- Сложнее логика с OAM CFM между edge и spine уровнями.
Минусы значительно превышают плюсы, идем дальше.
MC-LAG L2 Switched
Данный вариант продолжает все плюсы и минусы предыдущего варианта, но добавляет сложности, ведь, возникает проблема с BUM трафиком.
Сразу минус и идем дальше.
MC-LAG L3 Routed w/ BGP
Вот, что-то уже интересное, не так ли?
В данном сценарии у нас повторяется предыдущая схема, за исключением того, что fw превращаются в транзитные маршрутизаторы.
На edge/spine:
- От обоих устройств в MC-LAG паре собирается LAG к одному fw устройству;
- Для каждого fw назначается свой уникальный VLAN, чтобы изолировать BUM трафик. Если требуется несколько сервисов, то для их сегментации будет назначено несколько VLAN, но все они будут уникальными в рамках данной схемы;
- На edge/spine поднимаются виртуальные интерфейсы (IRB/BVI/VBDIF) с адресацией из сети /29 (да, IPv4);
- Поднимается по одной BGP сессии между fw и каждым коммутатором уровня edge/spine к их виртуальным интерфейсам.
Зачем нужно 2 BGP сессии и почему бы не поднять одну BGP сессию к виртуальному плавающему IP-адресу (VRRP/HSRP)? Потому, что, в случае аварии устройства, которое обслуживает в данный момент времени виртуальный IP-адрес, BGP сессия будет переустановлена на другом устройстве, это вызовет потерю трафика и отказ в обслуживании сервиса. Но, если поднять две BGP сессии от fw к паре коммутаторов одного уровня (edge/spine), то в случае аварии одного из коммутаторов, просто уберется NH из NHG, а потеря трафика будет менее значительной. При этом, если произойдет авария на линке, например, между fw01 и spine01, BGP сессия не упадет между данными устройствами, потому-что IP-адрес будет доступен от fw01 через spine02 по ICL. Да, перераспределятся hash-buckets, поменяется egress интерфейс, но результат прохождения потока будет сильно зависеть от конкретного силикона и ПО, а если точнее, то используется ли на устройстве иерархический ECMP/hashing, иерархический FIB, или нет.
Но, если мы получим асимметричное прохождение трафика, можно прибегнуть к решению проблемы, которое будет рассмотрено далее в секции ECMP w/ BGP.
Плюсы:
- В некоторых случаях удовлетворяет субсекундному схождению сети;
- В некоторых случаях решает проблему асимметричного прохождения трафика, но зависит от конкретного силикона и ПО.
Минусы:
- Отсутствие горизонтального масштабирования из-за MC-LAG - больше двух устройств в группе быть не может (однако, можно построить рядом аналогичную схему);
- Логика по предотвращению асимметрии ложится на ICL, что требует дополнительных интерфейсов:
- Чтобы ICL не являлся бутылочным горлышком, в идеальном сценарии, емкость ICL должна равняться сумме емкости всех fw (для 6 fw используется 6*100g линков, значит, емкость ICL должна быть 600g);
- SFP и оптика стоит денег, поэтому ICL будет стоить дороже;
- Кроме ICL, для предотвращения асимметрии, данный сценарий сильно зависит от аппаратных и программируемых возможностей силикона и ПО, что усложняет возможное масштабирование и предсказуемость.
- MC-LAG - тоже SPOF;
- Сложнее поиск и устранение неисправностей;
- Если требуется субсекундное схождение сети, то сперва требуется обеспечить высокую скорость (~300ms) детектирования аварии - связано с fw:
- EEM/скрипты сами по себе не быстро отрабатывают (CPU);
- Для OAM LFM требуется поддержка на аппаратном уровне;
- Сложнее логика с OAM CFM между edge и spine уровнями;
- Для BFD требуется поддержка на аппаратном уровне.
Вроде бы хороший вариант, а минусов с каждым разом все больше и больше, как же так.. А вот так :)
Вспоминая основы и де-факто стандарты построение современных сетей в ДЦ, можно придти к выводу, что, если смешать SP и DC технологии в одном флаконе, получится почти идеальное решение данной задачи. Идем к нему, осталось совсем чуть-чуть!
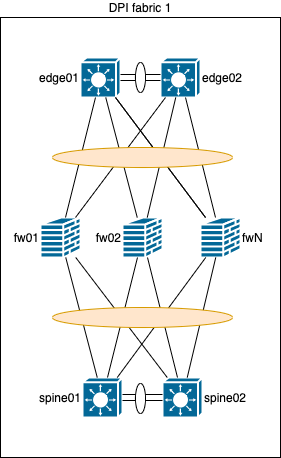
ECMP w/ BGP
Ура, наконец-то что-то простое! (нет)
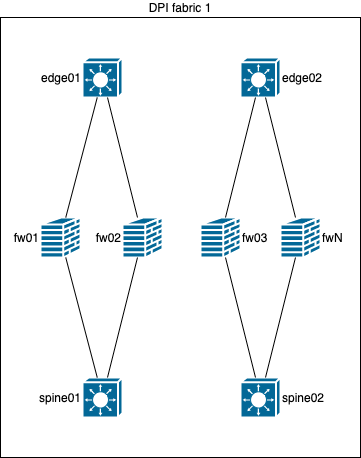
Схема сверху хороша, если резервирование можно обеспечить целыми плоскостями, а не отдельными устройствами, но, в нашем сценарии и с нашей емкостью этот вариант стоит дороже, поэтому, сперва решили сделать резервирование устройств внутри плоскости, чтобы защитится от двойного отказа, как на схеме ниже, а только потом, после исчерпания ресурсов, добавлять новую плоскость.
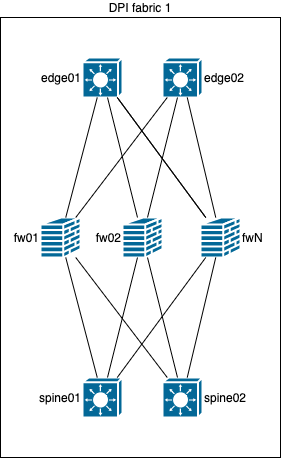
Тут прекрасно всё! (почти)
Перейдем же к описанию принципа работы:
- Каждое устройство на данной схеме является маршрутизатором;
- Поверх физических линков устанавливаются single-hop BGP сессии;
- На fw есть поддержка BFD на аппаратном уровне, поэтому, дополнительно настроен BFD на BGP сессии;
- Каждое устройство выполняет балансировку по ECMP;
- На fw настроен add-path и он отправляет не только best, а все префиксы на уровень edge/spine;
- На коммутаторах уровня edge и spine настроена балансировка по SRC/DST IP - это нужно для того, чтобы между одним и тем же endpoint, если используется несколько сессий (например: разные протоколы и/или разные порты), общий поток проходил всегда через один и тот же fw. Это обеспечит более точную аналитику и шанс позитивного срабатывания IPS (и уменьшит шанс ложного срабатывания IPS). С таким количеством SRC IP-адресов и паттерном трафика, балансировка не будет менее точной, а если и будет, то погрешность крайне мала;
- symmetric hashing - для симметричного прохождения потока всегда через один и тот же fw в обе стороны. Но, чтобы symmetric hashing работал как нужно, важно следующее:
- Устройства должны иметь идентичное количество hash-buckets;
- Устройства должны иметь идентичный offset;
- Устройства должны быть настроены на идентичную hash-function;
- Устройства должны иметь идентичное количество adjacency pointers, которые в свою очередь ссылаются на next-hop 1:1;
- А в некоторых случаях устройства должны иметь идентичную версию ПО.</br> Тут можно заметить, что этого крайне тяжело достичь, используя разных производителей и требует отдельного глубокого тестирования. В нашем случае все устройства edge/spine одного производителя, модели и имеют идентичную версию ПО.
- Resilient/consistent hashing - при использовании ECMP/LAG, в случае аварии на устройстве или на линке, предотвращает перебалансировку всех записей в hash-table (из-за изменения количества или перераспределения hash-buckets), что позитивно сказывается на сервисе и минимизирует потерю трафика.</br> Если коротко, то будет наблюдаться кратковременная потеря только того трафика, для которого egress интерфейс был изъят из NHG).
Что же, вроде все понятно, так почему большинство организаций до сих пор используют LAG, а не ECMP? Я думаю, дело в маркетинге, а может быть просто никому это не было нужно и все жили на scale-up. Но мы пришли к ECMP, и я повторюсь, аналогичных примеров использования ECMP я не нашел в русскоговорящем сегменте, а в англоязычном их были единицы и некоторые подразумевали sFlow аналитику прямо на коммутаторе с использованием самописных скриптов.
В данном сценарии все будет работать идеально, за исключением проблемы асимметричного прохождения трафика при одиночных отказах линков. Как ее решить? Первый вариант был описан в самой первой схеме с L2 и fw в прозрачном режиме, но, мы же не хотим переносить логику на fw. Пусть они останутся все теми же тупыми устройствами, но уже с BGP, BFD и ECMP. Кроме того, есть еще как минимум два решения данной проблемы, о которых будет в следующих подчастях, а пока подведем краткий итог.
Плюсы:
- Простая логика;
- Субсекундное схождение сети;
- ECMP обкатан многими производителями, что уменьшает вероятность встретить ошибку в ПО (но это не точно!);
- Асимметричное прохождение трафика решается при помощи symmetric hashing на ECMP (но сильно зависит от силикона и ПО);
- Минимум затрат и быстрый запуск;
- Возможно горизонтальное масштабирование;
- Один протокол - меньше вероятность ошибки в ПО и как следствие меньше вероятность аварии;
- Технологии старые с простой логикой, гораздо проще поиск и устранение неисправностей;
- Не требует горизонтальных линков для обхода трафика, что не будет являться бутылочным горлышком и удешевит итоговую стоимость решения;
Минусы:
- Требует соблюдения симметричной коммутации;
- Асимметричное прохождение трафика возникает при одиночных отказах линков к fw и требует дополнительной логики, что усложняет конструкцию:
- Туннелирование;
- Расширение логики маршрутизации при помощи BGP communities и политик маршрутизации.
- Если требуется субсекундное схождение сети, то сперва требуется обеспечить высокую скорость (~300ms) детектирования аварии - связано с fw:
- Для BFD требуется поддержка на аппаратном уровне.
Ну что, плюсов много, осталось слегка доработать и с этим можно жить!
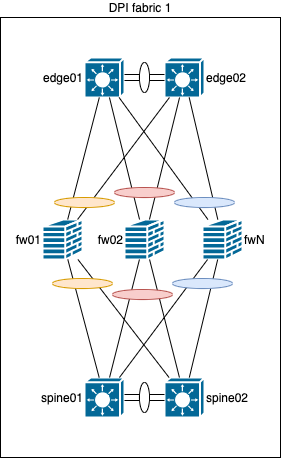
Tunneling GRE/IP-IP
Начинаем решать проблему асимметричного прохождения трафика с простого - с туннелирования.
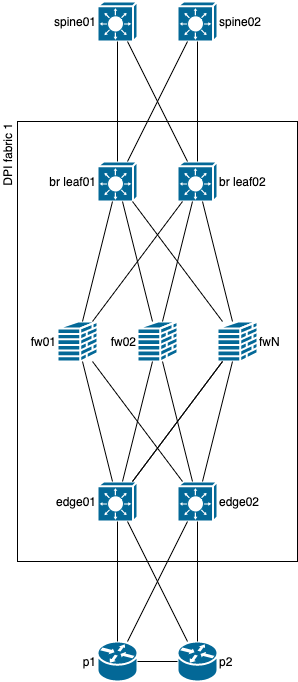
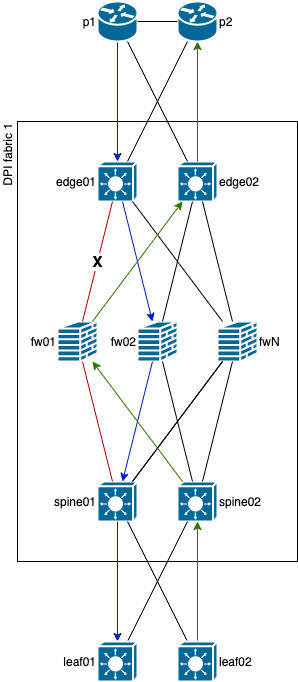
Для лучшего понимания концепции немного перерисована схема, в которой наши существующие spine превратились в border leafs и к ним добавился еще уровень spine (ну не будем же мы туннелировать трафик для обхода проблемного линка через пачку leaf коммутаторов), а к уровню edge добавилась пара LSR, чтобы в нижней части схемы тоже была возможность использовать туннелирование для обхода проблемного линка.
Предлагаю рассмотреть путь прохождения трафика от spine коммутаторов до p маршрутизаторов на схеме ниже.
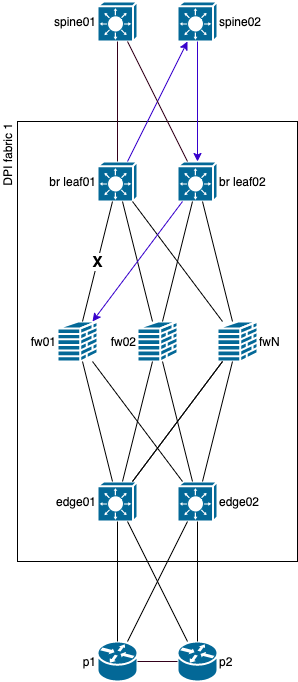
В данном схеме отображена авария на линке между br leaf01 и fw01, при этом, от br leaf01 дополнительно установлен туннель до fw01, позволяющий обойти проблемный линк через альтернативный путь. Конечно, в большинстве случаев и для обходного туннеля можно будет использовать ECMP, как на схеме ниже.
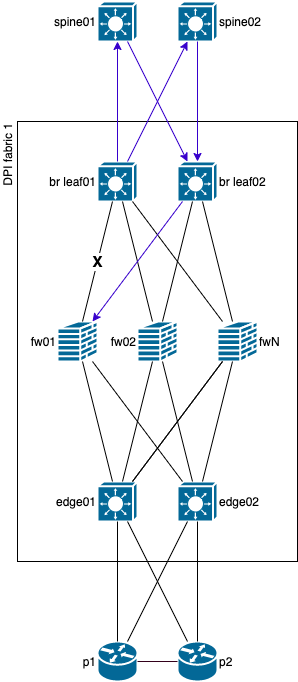
Это довольно хороший способ многократно зарекомендовавший себя, но, как видно по схеме, он требует дополнительного оборудования или изменения конфигурации сети ДЦ (сейчас CLOS дизайн, отсутствие BGP path hunting и все такое, построенное в лучший традициях), чего мы себе не могли позволить на тот момент. Кроме того, при использовании GRE могут возникнуть проблемы с offload на fw, особенно если у fw модульная архитектура внутри устройства (даже если устройство 1u, это не означает, что там будет обязательно 1 чип), поэтому и от GRE мы сразу отказались. А что на счет IP-IP? Это может показаться смешным, но мы его даже не тестировали на данном оборудовании в данном контексте, потому-что это все равно потребовало бы изменение дизайна ДЦ или покупки дополнительного уровня оборудования, кроме того, на наших QFX10k2 данная функциональность появилась только в 20.3 ветке ПО, которую нужно тестировать отдельно, а ПО относительно свежее, поэтому может потенциально быть не стабильным, а сроки никто не продлевал и бюджет не увеличивал. Но с IP-IP должно быть меньше проблем, чем с GRE, так как на используемых fw есть поддержка offload IP-IP туннелей.
Плюсы:
- Субсекундное схождение сети при помощи заранее подготовленного туннеля для обхода проблемного линка;
- Относительная простота конфигурации;
- Относительная простота поиска и исправления неисправностей.
Минусы:
- Требует дополнительного оборудования или изменения политики маршрутизации для заворачивания трафика через leaf коммутаторы;
- Возможны проблемы с offload на fw, в зависимости от производителя/модели оборудования и используемого протокола.
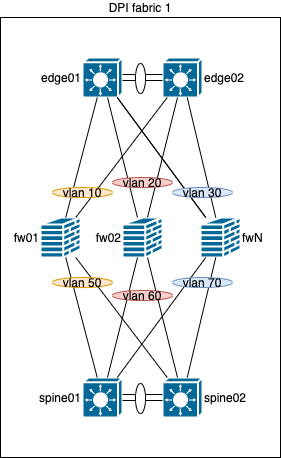
BGP communities
Если б не было тебя BGP, не было бы communities, значит и не было бы этого решения задачи.
Это довольно интересное и не сложное решение задачи, но, при этом, сильно зависит от производительности control plane всех устройств и стабильности ПО, а также, в зависимости от количества устройств (масштабирования) экспоненциально увеличивает итоговую конфигурацию в размере.
RT community
Пожалуй, самое логичное и в то же время самое сложное для понимания решение, если с этим не работал ранее, но мы же тут все матерые сетевики, не так ли? Смысл простой, как и всегда - route target extended community (далее community) является в данном сценарии логической “меткой” (не путать с MPLS label), при получении префикса, помеченного которым(и), мы принимаем то или иное действие. В нашем сценарии ассоциируем возможный путь прохождения трафика (конечно это не LSP по ERO..) с уникальным значением community и добавляем данный(ые) community к префиксу.
Например: чтобы не использовать логику на fw, мы просто маркируем префиксы, полученные/сгенерированные на edge, community с определенным значением, за которым скрывается соответствие определенному действию, и отправляем данный префикс с данным community на fw. Поскольку данное community является транзитивным, то fw просто передает префикс с этим community дальше, на spine, не меняя его. На spine настраивается политика маршрутизации, в которой указано что требуется сделать, когда от fw придет префикс с определенным community, (например: изменить next-hop или сбросить префикс). В то же время, если приходит префикс без указанного community, то данный префикс будет сброшен по умолчанию (default reject). В обратном направлении распространение префиксов происходит аналогичным образом, добавляя к префиксу определенный(ые) community, которое(ые) ассоциируется с возможным путем прохождения трафика, по которому будет принято то или иное действие.
Открываем нашу старую целевую в PDF и смотрим детальнее, как это выглядит:
- Поскольку edge у нас является MPLS PE устройством и принимает множество префиксов в нашем домене маршрутизации, а мы не хотим отправлять все эти префиксы на fw, мы агрегируем на edge все префиксы до
0/0и отправляем0/0, например, на fw01, дополнительно маркируя данный префикс RT community 65001:111 и 65001:112, что обозначает возможность прохождения трафика по двум путям через данный МСЭ:- *:111 - edge01 - fw01 - spine01;
- *:112 - edge01 - fw01 - spine02.
- fw01 пересылает данный префикс с community без изменений на spine01 и spine02;
- Например, на spine01 настроена политика маршрутизации, в которой указано:
term 1 { from { community path_111; route-filter 0.0.0.0/0 exact; } then { community set vpnX-default; next-hop 169.254.101.1; accept; } }Исходя из данной настройки можно заметить:
- Принимается префикс строго
0/0и сcommunity path_111, которое имеет значениеtarget:65001:111, которое мы как раз ассоциировали с данным путем; - Далее, выполняется операция
community set vpnX-default, которая убирает все ранее назначенные communities и назначает новое, ассоциированное с конкретным VPN, которое мы уже будем экспортировать в RI и импортировать в RI на leaf коммутаторах; - Кроме того, устанавливается next-hop равный p2p IP-адресу BGP соседа, сессия с которым является single-hop и настроена на непосредственно подключенном интерфейса;
- И
accept, как же без него. :)
- Принимается префикс строго
- На spine02 точно такая-же политика маршрутизации, за исключением:
community path_112, которое имеет значениеtarget:65001:112, которое мы как раз ассоциировали с данным путем;- next-hop равный p2p IP-адресу BGP соседа, сессия с которым является single-hop и настроена на непосредственно подключенном интерфейса (мы же не можем в одном VPN на одном устройстве использовать одинаковые IP-адреса для установки множества BGP сессий в данной топологии);
- Данная политика маршрутизации применяется на соседство по BGP с fw01 в направление in (для других fw созданы и применены аналогичные политики маршрутизации).</br> Распространение маршрутной информации в обратном направлении и применение действия по заданным критериям происходит аналогичным образом.
Исходя из логики настройки и работы вышеупомянутой симметричной схемы на control plane, мы получаем возможность увести логику по предотвращению проблемы асимметричного прохождения трафика при аварии на одном линке к fw, от fw на уровни edge и spine.
Если коротко, каким образом предотвращается асимметричное прохождения трафика, например:
- Упал интерфейс между fw01 и edge01;
- На fw01 происходит обновление RIB, и он отзывает префикс у spine01 и spine02;
- Как следствие, на spine уровень не приходит данный префикс с
community path_111; - spine01 не находит в принятых анонсах префикс с
community path_111и как следствие, условие политики маршрутизации не выполняется, значит не для чего будет менять next-hop, и данный интерфейс (BGP сосед) просто не будет использоваться как активный next-hop.
На fw и на edge/spine на BGP соседстве с fw, в обязательном порядке должна быть выключена задержка отправки BGP UPDATE Message (eg rapid-withdrawal), это позволит быстрее реагировать при проблемах на не симметричных отказах СПД. В некоторых случаях может понадобится поменять таймеры для процесса BGP и/или его pipeline (eg bgp scan-time).
К тому же, следует следить за загрузкой control plane и за состоянием стабильности сети, это напрямую влияет на скорость сходимости сети при высокой нагрузке и горизонтальном масштабировании.
Плюсы:
- Субсекундное схождение сети при помощи быстрого обновления RIB (FIB то обновляется гораздо быстрее, ага) и отправки BGP UPDATE Message для изменения next-hop с целью обхода проблемного линка;
- Относительная простота конфигурации;
- Относительная простота поиска и исправления неисправностей.
Минусы:
- В некоторых случаях при работе с определенным оборудованием схема усложняется из-за дополнительного тюнинга таймеров различных процессов и т.п.;
- Чем больше устройств и чем выше масштабирование, тем сложнее конфигурация и дольше по времени обновление RIB/FIB (поэтому мы решили делать небольшие плоскости для IPS фабрик);
- Требуется следить за стабильностью сети и загрузкой control plane устройств (в прочем, как и всегда);
- Даже в такой схеме можно получить асимметричное прохождение трафика, если произойдет авария на линке, например, между edge01 и fw01, а трафик в рамках конкретного flow будет направлен в фабрику через edge01, а при прохождении в обратную сторону, будет направлен через spine02. У edge01 не будет других вариантов (если не использовать туннелирование), кроме как выбрать NH из доступных (минус один от исходного), тогда как на spine02 будет другое кол-во доступных NH и соответственно egress interface будут отличаться, что в свою очередь приведет к прохождению трафика через разные fw устройства, что и является асимметрией. Схема для наглядности ниже.
Часть плюсов и минусов наследуется из родительской секцииECMP w/ BGP.
Link bandwidth community
В данной секции не могу не упомянуть BGP Link Bandwidth Extended Community, которое позволяет прибегнуть к распределению нагрузки по UCMP, используя BW community, которыми можно “помечать” префиксы полученные через single-hop BGP сессии, и тем самым передавать BGP соседям информацию о скорости интерфейса, в следствии чего, можно масштабировать фабрику используя устройства или целые плоскости разной производительности. Раз уж зашли про целые плоскости, то можно передавать вышестоящим и нижестоящим BGP соседям aggregate bandwidth для применения балансировки по UCMP между целыми плоскостями, если вдруг внутри какой-то из плоскостей случится авария.
И поскольку я уже неоднократно говорил про плоскости, ниже схема IPS фабрики с двумя плоскостями.
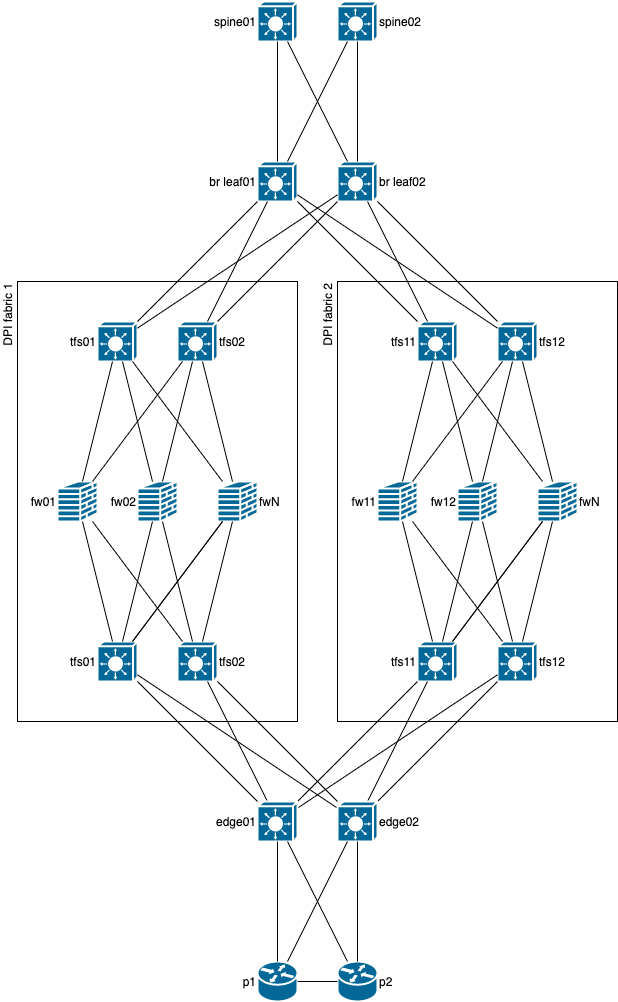
В данной схеме видно, что уровни edge/br leaf заменяются на уровень tfs, который в свою очередь уже подключаются к edge/br leaf коммутаторам.
Но почему бы их не подключить сразу к p/spine коммутаторам, как на схеме ниже?
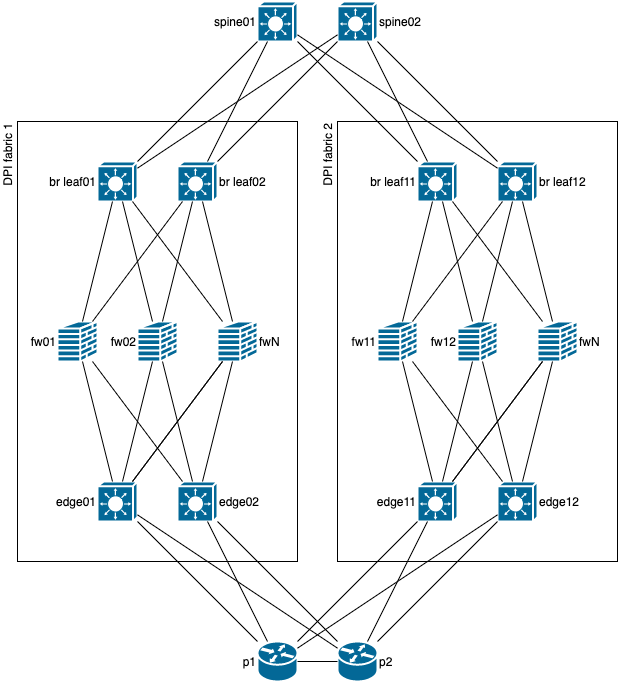
Во первых - масштабирование и высокая стоимость интерфейсов spine/p устройств, а во вторых, все по той же причине, связанной с symmetric hashing - flow нужно балансировать теперь еще и по плоскостям, симметрично в оба направления, чтобы не было потери трафика из-за отсутствия синхронизации состояния flow на fw, и чтобы это сделать правильно, вспоминаем условия симметричной балансировки, и делаем вывод, что для агрегации разных плоскостей, нужны еще устройства, удовлетворяющие решению задачи симметричной балансировки.
Конечно, в stateless сети мы могли бы назначить стоимость каждого интерфейса, например, в плоскости 1 равной 100g, а в плоскости 2 равной 40g и после чего передать aggregate bandwidth на edge/br leaf коммутаторы, которые бы уже равномерно разбалансировали трафик по разным плоскостям, а если бы случилась авария на линке или fw внутри какой-либо плоскости, то aggregate bandwidth бы поменялось и поменялось бы распределение трафика по плоскостям. Но, у нас ведь есть stateful устройства на сети, поэтому, есть вероятность, что данное решение не будет применимо. Однако, следует еще протестировать данное решение, ведь есть вероятность, что в зависимости от реализации, в случае аварии, вызывающей изменение aggregate bandwidth, resilient hashing сможет предотвратить перераспределение всего трафика между плоскостями, а для проблемы с асимметричным прохождением трафика нам помогут все те же знакомые действующие лица: транзитивные route target extended community и политики маршрутизации.
Выводы делайте сами, данное решение в stateful сети еще мною не тестировалось, но потенциал у данного решения определенно есть!
Целевая схема одной DPI фабрики
Все же, жизнь не кажется сказкой и исходя из всех предыдущих вариантов, всех проблем, которые могут возникнуть, для решения проблемы асимметричного прохождения трафика при одиночных или двойных отказах, самым очевидным становится следующий вариант, схема которого ниже.
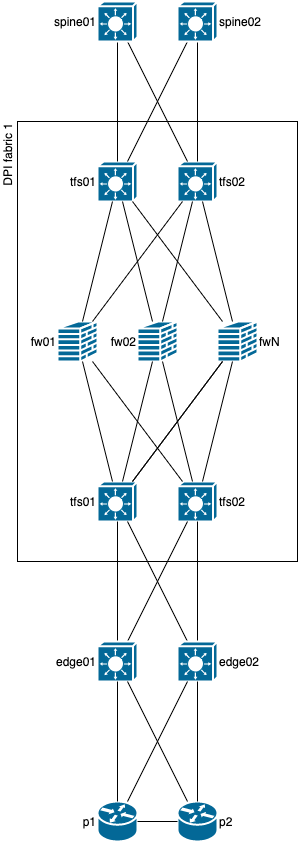
Да, логика данного варианта описана в предыдущей секции ‘Link bandwidth community’ и она прекрасно подходит под использование всего одной DPI фабрики.
Какие же особенности в ней есть? Используется все тот же BGP, та же логика с RT communities (только вся логика теперь не на edge/spine, а на tfs, естественно), та же логика с симметричной балансировкой и коммутацией. Но! Добавляется еще один уровень между fw и edge/spine, который на схеме называется tfs. Ключевым является то, что данный уровень может использоваться сразу для решения нескольких задач, он может быть не обязательно умным (а значит будет дешевым), но самое важное, чтобы была поддержка BGP, ECMP с применением симметричной балансировки и vrf-lite подобных механизмов. Этот уровень нужен для того, чтобы можно было “нормализовать” прохождение трафика внутри DPI фабрики в случае одиночного или двойного отказа на линках, при помощи симметричной балансировки. Кроме того, для увеличения скорости сходимости сети, данный уровень может использовать обходные туннели через edge/spine, чего раньше мы не могли себе позволить с leaf коммутаторами.
Все те же плюсы и минусы из предыдущих пунктов, но есть что добавить нового. Плюсы:
- Полностью позволяет избежать проблемы асимметричного прохождения трафика при помощи симметричной балансировки на нескольких уровнях;
- Позволяет избежать проблемы асимметричного прохождения трафика при помощи обходных туннелей через edge/spine.
Минусы:
- Данная схема стоит дороже, так как требуются еще коммутаторы (но это могут быть не дорогие коммутаторы без MPLS, без VXLAN или других сложных в реализации технологий);
- Данная схема требует симметричной коммутации для нескольких уровней устройств сразу;
- Данная схема сложнее в настройке, эксплуатации, поиске и устранении неисправностей, больше потребляет места в стойке, больше потребляет ЭП, больше выделяет тепла (но это может быть понятно и из предыдущих пунктов).
Проблемы
Проблем, как ты можешь заметить, дорогой читатель, предостаточно, но, все же, оптимальное решение поставленной задачи найдено, протестировано и введено в эксплуатацию.
Перейдем к разбору некоторых проблем:
- Отсутствие кластеризации само по себе не является проблемой, но проблемой является отсутствие синхронизации результата работы IPS движка, потому-что, в зависимости от устройства и ПО, мы можем получить или потерю трафика, или пропуск нежелательного трафика, поэтому, симметричная балансировка важна и нужна;
- Однажды была проблема, когда активное устройство в a/s кластере было загружено на ~60% и при аварийном переключении нагрузки на резервное устройство, резервное устройство не выдержало и вошло в сберегательный режим, что не позволило устанавливать новые соединения через данное устройство и вызвало частичный отказ;
- Есть проблема в сложности данной реализации, ведь, не просто так нет детализированных схем в публичном сегменте;
- Не все всегда работает так, как должно работать.
Конфигурация
Вот и дошли мы до финального аккорда, который будет самым длинным, но не менее важным! В конкретном примере мы рассмотрим конфигурацию edge, но для spine и tfs коммутаторов конфигурация не будет сильно отличаться
- Конфигурация по частям с их описанием:
- Версия ПО:
version 20.3R3.8; - Группы конфигурации для уменьшения этой самой конфигурации в дальнейшем:
groups { ri-vrf { routing-instances { <*> { routing-options { multipath; protect core; auto-export; } instance-type vrf; vrf-table-label; } } } ospf-bb { protocols { ospf { area 0.0.0.0 { interface <*> { interface-type p2p; node-link-protection; flood-reduction; bfd-liveness-detection { version automatic; minimum-interval 300; multiplier 3; } ldp-synchronization; } } } } } } - Имя устройства:
system { host-name edge01; } - Конфигурация шасси устройства для возможности использования 100g интерфейсов:
chassis { fpc 0 { pic 0 { port 1 { speed 100g; } port 5 { speed 100g; } port 7 { speed 100g; } port 11 { speed 100g; } port 13 { speed 100g; } port 17 { speed 100g; } port 19 { speed 100g; } port 23 { speed 100g; } port 25 { speed 100g; } port 29 { speed 100g; } port 31 { speed 100g; } port 35 { speed 100g; } } } } - Конфигурация интерфейсов:
interfaces { et-0/0/1 { description "link with fw1"; vlan-tagging; mtu 9192; unit 10 { vlan-id 10; family inet { address 169.254.201.1/31; } } unit 11 { vlan-id 11; family inet { address 169.254.201.3/31; } } unit 12 { vlan-id 12; family inet { address 169.254.201.5/31; } } } et-0/0/5 { apply-groups interface-mpls; description "link with p1"; mtu 9192; unit 0 { family inet { address 10.100.4.84/31; } } } et-0/0/7 { description "link with fw2"; vlan-tagging; mtu 9192; unit 10 { vlan-id 10; family inet { address 169.254.201.33/31; } } unit 11 { vlan-id 11; family inet { address 169.254.201.35/31; } } unit 12 { vlan-id 12; family inet { address 169.254.201.37/31; } } } et-0/0/11 { apply-groups interface-mpls; description "link with p2"; mtu 9192; unit 0 { family inet { address 10.100.4.86/31; } } } }Прошу заметить, что данное устройства имеет 4*100g интерфейса на одном ASIC, поэтому, логичнее интерфейсы распределять группами по ASIC, например: 2 интерфейса в направление вверх, 2 интерфейса вниз. И напоминаю, что на устройстве spine01 коммутация будет симметричной для обеспечения симметричной балансировки.
- Параметры балансировки на устройстве:
forwarding-options { enhanced-hash-key { hash-seed { 0; } resilient-hash-seed { 0; } layer2 { no-incoming-port; no-vlan-id; } inet { no-incoming-port; no-l4-source-port; no-l4-destination-port; } inet6 { no-incoming-port; no-l4-source-port; no-l4-destination-port; } no-mpls; } } - Политики, которые многим будут хорошо знакомы. В частности, политика для балансировки per-flow (пусть не смутит тебя per-packet), политика для generate префикса, политика NHS:
policy-options { policy-statement PFE-LB { term 1 { then { load-balance per-packet; } } } policy-statement generate-route { from { protocol bgp; route-filter 0.0.0.0/0 orlonger; } then accept; } policy-statement next-hop-self { term 1 { from protocol bgp; then { next-hop self; accept; } } } - Политики для RI VRF import/export:
policy-options { policy-statement vpn1_export { term other { from protocol bgp; then { community add vpn1; accept; } } term default { then reject; } } policy-statement vpn1_import { term other { from { protocol bgp; community vpn1; } then accept; } term default { then reject; } } policy-statement vpn2_export { term other { from protocol bgp; then { community add vpn2; accept; } } term default { then reject; } } policy-statement vpn2_import { term other { from { protocol bgp; community vpn2; } then accept; } term default { then reject; } } policy-statement vpn3_export { term other { from protocol bgp; then { community add vpn3; accept; } } term default { then reject; } } policy-statement vpn3_import { term other { from { protocol bgp; community vpn3; } then accept; } term default { then reject; } } } - Политики для применения на single-hop BGP сессии (в данном примере используется метод удаления и добавления community через set, однако, это лишь для примера. В реальном сценарии используется
delete community *:*и затемadd community X,Y):policy-options { policy-statement pl-vpn1-as65001-169.254.201.0-in { term 1 { from community path_111; then { community set vpn1; next-hop 169.254.201.0; accept; } } } policy-statement pl-vpn1-as65001-169.254.201.0-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_111; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } policy-statement pl-vpn1-as65001-169.254.201.32-in { term 1 { from community path_121; then { community set vpn1; next-hop 169.254.201.32; accept; } } } policy-statement pl-vpn1-as65001-169.254.201.32-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_121; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } policy-statement pl-vpn2-as65001-169.254.201.2-in { term 1 { from community path_111; then { community set vpn2; next-hop 169.254.201.2; accept; } } } policy-statement pl-vpn2-as65001-169.254.201.2-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_111; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } policy-statement pl-vpn2-as65001-169.254.201.34-in { term 1 { from community path_121; then { community set vpn2; next-hop 169.254.201.34; accept; } } } policy-statement pl-vpn2-as65001-169.254.201.34-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_121; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } policy-statement pl-vpn3-as65001-169.254.201.36-in { term 1 { from community path_121; then { community set vpn3; next-hop 169.254.201.36; accept; } } } policy-statement pl-vpn3-as65001-169.254.201.36-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_121; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } policy-statement pl-vpn3-as65001-169.254.201.4-in { term 1 { from community path_111; then { community set vpn3; next-hop 169.254.201.4; accept; } } } policy-statement pl-vpn3-as65001-169.254.201.4-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_111; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } } - Ну и собственно набор communities:
policy-options { community vpn1 members target:65001:1; community vpn2 members target:65001:2; community vpn3 members target:65001:3; community path_111 members target:65001:111; community path_112 members target:65001:112; community path_121 members target:65001:121; community path_122 members target:65001:122; community path_211 members target:65001:211; community path_212 members target:65001:212; community path_221 members target:65001:221; community path_222 members target:65001:222; } - Конфигурация RI VRF:
routing-instances { vpn1 { apply-groups ri-vrf; routing-options { generate { route 0.0.0.0/0 { policy generate-route; preference 200; discard; } } } protocols { bgp { group fw { type external; local-as 65535; multipath { multiple-as; } bfd-liveness-detection { version automatic; minimum-interval 1000; multiplier 3; session-mode automatic; } neighbor 169.254.201.0 { local-address 169.254.201.1; import pl-vpn1-as65001-169.254.201.0-in; export pl-vpn1-as65001-169.254.201.0-out; peer-as 65001; graceful-restart; } neighbor 169.254.201.32 { local-address 169.254.201.33; import pl-vpn1-as65001-169.254.201.32-in; export pl-vpn1-as65001-169.254.201.32-out; peer-as 65001; graceful-restart; } } } } interface et-0/0/1.10; interface et-0/0/7.10; vrf-import vpn1_import; vrf-export vpn1_export; } vpn2 { apply-groups ri-vrf; routing-options { generate { route 0.0.0.0/0 { policy generate-route; preference 200; discard; } } } protocols { bgp { group fw { type external; local-as 65535; multipath { multiple-as; } bfd-liveness-detection { version automatic; minimum-interval 1000; multiplier 3; session-mode automatic; } neighbor 169.254.201.2 { local-address 169.254.201.3; import pl-vpn2-as65001-169.254.201.2-in; export pl-vpn2-as65001-169.254.201.2-out; peer-as 65001; graceful-restart; } neighbor 169.254.201.34 { local-address 169.254.201.35; import pl-vpn2-as65001-169.254.201.34-in; export pl-vpn2-as65001-169.254.201.34-out; peer-as 65001; graceful-restart; } } } } interface et-0/0/1.11; interface et-0/0/7.11; vrf-import vpn2_import; vrf-export vpn2_export; } vpn3 { apply-groups ri-vrf; routing-options { generate { route 0.0.0.0/0 { policy generate-route; preference 200; discard; } } } protocols { bgp { group fw { type external; local-as 65535; multipath { multiple-as; } bfd-liveness-detection { version automatic; minimum-interval 1000; multiplier 3; session-mode automatic; } neighbor 169.254.201.4 { local-address 169.254.201.5; import pl-vpn3-as65001-169.254.201.4-in; export pl-vpn3-as65001-169.254.201.4-out; peer-as 65001; graceful-restart; } neighbor 169.254.201.36 { local-address 169.254.201.37; import pl-vpn3-as65001-169.254.201.36-in; export pl-vpn3-as65001-169.254.201.36-out; peer-as 65001; graceful-restart; } } } } interface et-0/0/1.12; interface et-0/0/7.12; vrf-import vpn3_import; vrf-export vpn3_export; } } - Конфигурация routing-options с экспортом политик маршрутизации для forwarding-table, CNS, ECMP FRR и прочих полезных настроек:
routing-options { route-distinguisher-id 10.100.0.238; forwarding-table { export PFE-LB; ecmp-fast-reroute; chained-composite-next-hop { ingress { l3vpn; } } } resolution { rib bgp.rtarget.0 { resolution-ribs inet.0; } } router-id 10.100.0.238; autonomous-system 65535; aggregate { defaults { discard; } } protect core; } - Конфигурация протоколов маршрутизации и остальных (Можно заметить, что BFD в конфигурации имеет таймер 1с. Этот параметр сильно зависит от платформы и ПО, но после положительных результатов тестирования более низкого таймера на используемых нами устройства, конфигурация будет изменена, а заметка обновлена):
protocols { bgp { vpn-apply-export; group internal { type internal; local-address 10.100.0.238; family inet-vpn { unicast { output-queue-priority priority 3; route-refresh-priority priority 3; } } family route-target { output-queue-priority priority 16; route-refresh-priority priority 16; } export next-hop-self; peer-as 65535; local-as 65535; neighbor 10.100.0.243; neighbor 10.100.0.244; } local-preference 350; mtu-discovery; log-updown; damping; graceful-restart; multipath; bfd-liveness-detection { version automatic; minimum-interval 1000; multiplier 3; session-mode automatic; } multipath-build-priority { low; } } ldp { auto-targeted-session; track-igp-metric; mtu-discovery; deaggregate; interface et-0/0/5.0 { link-protection; } interface et-0/0/11.0 { link-protection; } interface fxp0.0 { disable; } interface lo0.0; session-protection; } mpls { interface fxp0.0 { disable; } interface et-0/0/5.0; interface et-0/0/11.0; } ospf { backup-spf-options { remote-backup-calculation; per-prefix-calculation all; node-link-degradation; } traffic-engineering; area 0.0.0.0 { interface lo0.0 { passive; } interface fxp0.0 { disable; } interface et-0/0/5.0 { apply-groups ospf-bb; } interface et-0/0/11.0 { apply-groups ospf-bb; } } spf-options { delay 50; holddown 5000; rapid-runs 3; } reference-bandwidth 100g; lsa-refresh-interval 30; no-rfc-1583; } lldp { port-id-subtype interface-name; neighbour-port-info-display port-id; interface all; } lldp-med { interface all; } }
- Версия ПО:
- Конфигурация целиком:
version 20.3R3.8; groups { ri-vrf { routing-instances { <*> { routing-options { multipath; protect core; auto-export; } instance-type vrf; vrf-table-label; } } } ospf-bb { protocols { ospf { area 0.0.0.0 { interface <*> { interface-type p2p; node-link-protection; flood-reduction; bfd-liveness-detection { version automatic; minimum-interval 300; multiplier 3; } ldp-synchronization; } } } } } } system { host-name edge01; } chassis { fpc 0 { pic 0 { port 1 { speed 100g; } port 5 { speed 100g; } port 7 { speed 100g; } port 11 { speed 100g; } port 13 { speed 100g; } port 17 { speed 100g; } port 19 { speed 100g; } port 23 { speed 100g; } port 25 { speed 100g; } port 29 { speed 100g; } port 31 { speed 100g; } port 35 { speed 100g; } } } } interfaces { et-0/0/1 { description "link with fw1"; vlan-tagging; mtu 9192; unit 10 { vlan-id 10; family inet { address 169.254.201.1/31; } } unit 11 { vlan-id 11; family inet { address 169.254.201.3/31; } } unit 12 { vlan-id 12; family inet { address 169.254.201.5/31; } } } et-0/0/5 { apply-groups interface-mpls; description "link with p1"; mtu 9192; unit 0 { family inet { address 10.100.4.84/31; } } } et-0/0/7 { description "link with fw2"; vlan-tagging; mtu 9192; unit 10 { vlan-id 10; family inet { address 169.254.201.33/31; } } unit 11 { vlan-id 11; family inet { address 169.254.201.35/31; } } unit 12 { vlan-id 12; family inet { address 169.254.201.37/31; } } } et-0/0/11 { apply-groups interface-mpls; description "link with p2"; mtu 9192; unit 0 { family inet { address 10.100.4.86/31; } } } lo0 { unit 0 { description "GRT OSPF"; family inet { address 10.100.0.238/32; } } } } forwarding-options { enhanced-hash-key { hash-seed { 0; } resilient-hash-seed { 0; } layer2 { no-incoming-port; no-vlan-id; } inet { no-incoming-port; no-l4-source-port; no-l4-destination-port; } inet6 { no-incoming-port; no-l4-source-port; no-l4-destination-port; } no-mpls; } } policy-options { policy-statement PFE-LB { term 1 { then { load-balance per-packet; } } } policy-statement generate-route { from { protocol bgp; route-filter 0.0.0.0/0 orlonger; } then accept; } policy-statement next-hop-self { term 1 { from protocol bgp; then { next-hop self; accept; } } } policy-statement vpn1_export { term other { from protocol bgp; then { community add vpn1; accept; } } term default { then reject; } } policy-statement vpn1_import { term other { from { protocol bgp; community vpn1; } then accept; } term default { then reject; } } policy-statement vpn2_export { term other { from protocol bgp; then { community add vpn2; accept; } } term default { then reject; } } policy-statement vpn2_import { term other { from { protocol bgp; community vpn2; } then accept; } term default { then reject; } } policy-statement vpn3_export { term other { from protocol bgp; then { community add vpn3; accept; } } term default { then reject; } } policy-statement vpn3_import { term other { from { protocol bgp; community vpn3; } then accept; } term default { then reject; } } policy-statement pl-vpn1-as65001-169.254.201.0-in { term 1 { from community path_111; then { community set vpn1; next-hop 169.254.201.0; accept; } } } policy-statement pl-vpn1-as65001-169.254.201.0-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_111; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } policy-statement pl-vpn1-as65001-169.254.201.32-in { term 1 { from community path_121; then { community set vpn1; next-hop 169.254.201.32; accept; } } } policy-statement pl-vpn1-as65001-169.254.201.32-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_121; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } policy-statement pl-vpn2-as65001-169.254.201.2-in { term 1 { from community path_111; then { community set vpn2; next-hop 169.254.201.2; accept; } } } policy-statement pl-vpn2-as65001-169.254.201.2-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_111; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } policy-statement pl-vpn2-as65001-169.254.201.34-in { term 1 { from community path_121; then { community set vpn2; next-hop 169.254.201.34; accept; } } } policy-statement pl-vpn2-as65001-169.254.201.34-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_121; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } policy-statement pl-vpn3-as65001-169.254.201.36-in { term 1 { from community path_121; then { community set vpn3; next-hop 169.254.201.36; accept; } } } policy-statement pl-vpn3-as65001-169.254.201.36-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_121; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } policy-statement pl-vpn3-as65001-169.254.201.4-in { term 1 { from community path_111; then { community set vpn3; next-hop 169.254.201.4; accept; } } } policy-statement pl-vpn3-as65001-169.254.201.4-out { term send-generate { from { route-filter 0.0.0.0/0 exact; } then { community set path_111; accept; } } term suppress-specific-routes { from { route-filter 0.0.0.0/0 longer; } then reject; } } community vpn1 members target:65001:1; community vpn2 members target:65001:2; community vpn3 members target:65001:3; community path_111 members target:65001:111; community path_112 members target:65001:112; community path_121 members target:65001:121; community path_122 members target:65001:122; community path_211 members target:65001:211; community path_212 members target:65001:212; community path_221 members target:65001:221; community path_222 members target:65001:222; } routing-instances { vpn1 { apply-groups ri-vrf; routing-options { generate { route 0.0.0.0/0 { policy generate-route; preference 200; discard; } } } protocols { bgp { group fw { type external; local-as 65535; multipath { multiple-as; } bfd-liveness-detection { version automatic; minimum-interval 1000; multiplier 3; session-mode automatic; } neighbor 169.254.201.0 { local-address 169.254.201.1; import pl-vpn1-as65001-169.254.201.0-in; export pl-vpn1-as65001-169.254.201.0-out; peer-as 65001; graceful-restart; } neighbor 169.254.201.32 { local-address 169.254.201.33; import pl-vpn1-as65001-169.254.201.32-in; export pl-vpn1-as65001-169.254.201.32-out; peer-as 65001; graceful-restart; } } } } interface et-0/0/1.10; interface et-0/0/7.10; vrf-import vpn1_import; vrf-export vpn1_export; } vpn2 { apply-groups ri-vrf; routing-options { generate { route 0.0.0.0/0 { policy generate-route; preference 200; discard; } } } protocols { bgp { group fw { type external; local-as 65535; multipath { multiple-as; } bfd-liveness-detection { version automatic; minimum-interval 1000; multiplier 3; session-mode automatic; } neighbor 169.254.201.2 { local-address 169.254.201.3; import pl-vpn2-as65001-169.254.201.2-in; export pl-vpn2-as65001-169.254.201.2-out; peer-as 65001; graceful-restart; } neighbor 169.254.201.34 { local-address 169.254.201.35; import pl-vpn2-as65001-169.254.201.34-in; export pl-vpn2-as65001-169.254.201.34-out; peer-as 65001; graceful-restart; } } } } interface et-0/0/1.11; interface et-0/0/7.11; vrf-import vpn2_import; vrf-export vpn2_export; } vpn3 { apply-groups ri-vrf; routing-options { generate { route 0.0.0.0/0 { policy generate-route; preference 200; discard; } } } protocols { bgp { group fw { type external; local-as 65535; multipath { multiple-as; } bfd-liveness-detection { version automatic; minimum-interval 1000; multiplier 3; session-mode automatic; } neighbor 169.254.201.4 { local-address 169.254.201.5; import pl-vpn3-as65001-169.254.201.4-in; export pl-vpn3-as65001-169.254.201.4-out; peer-as 65001; graceful-restart; } neighbor 169.254.201.36 { local-address 169.254.201.37; import pl-vpn3-as65001-169.254.201.36-in; export pl-vpn3-as65001-169.254.201.36-out; peer-as 65001; graceful-restart; } } } } interface et-0/0/1.12; interface et-0/0/7.12; vrf-import vpn3_import; vrf-export vpn3_export; } } routing-options { route-distinguisher-id 10.100.0.238; forwarding-table { export PFE-LB; ecmp-fast-reroute; chained-composite-next-hop { ingress { l3vpn; } } } resolution { rib bgp.rtarget.0 { resolution-ribs inet.0; } } router-id 10.100.0.238; autonomous-system 65535; aggregate { defaults { discard; } } protect core; } protocols { bgp { vpn-apply-export; group internal { type internal; local-address 10.100.0.238; family inet-vpn { unicast { output-queue-priority priority 3; route-refresh-priority priority 3; } } family route-target { output-queue-priority priority 16; route-refresh-priority priority 16; } export next-hop-self; peer-as 65535; local-as 65535; neighbor 10.100.0.243; neighbor 10.100.0.244; } local-preference 350; mtu-discovery; log-updown; damping; graceful-restart; multipath; bfd-liveness-detection { version automatic; minimum-interval 1000; multiplier 3; session-mode automatic; } multipath-build-priority { low; } } ldp { auto-targeted-session; track-igp-metric; mtu-discovery; deaggregate; interface et-0/0/5.0 { link-protection; } interface et-0/0/11.0 { link-protection; } interface fxp0.0 { disable; } interface lo0.0; session-protection; } mpls { interface fxp0.0 { disable; } interface et-0/0/5.0; interface et-0/0/11.0; } ospf { backup-spf-options { remote-backup-calculation; per-prefix-calculation all; node-link-degradation; } traffic-engineering; area 0.0.0.0 { interface lo0.0 { passive; } interface fxp0.0 { disable; } interface et-0/0/5.0 { apply-groups ospf-bb; } interface et-0/0/11.0 { apply-groups ospf-bb; } } spf-options { delay 50; holddown 5000; rapid-runs 3; } reference-bandwidth 100g; lsa-refresh-interval 30; no-rfc-1583; } lldp { port-id-subtype interface-name; neighbour-port-info-display port-id; interface all; } lldp-med { interface all; } }
Заключение
С улыбкой и болью вспоминаю фразу из притчи “о доверии (вендорам)” Марата Сибгатулина с linkmeetup: “на интеграционные тесты вендора не полагайся - сам организуй синтетические и продуктивные тесты.”.
На этапе внедрения нас ждали проблемы на каждом из уровней взаимодействия с данной схемой, на разных производителях, разных платформах и моделях:
- p маршрутизаторы теряли трафик, который заходил в новые 100g линейные карты и должен был выйти через старые 10g карты (на этапе миграции), через конкретный LSP, при этом, проблем не было при направлении трафика в другие LSP - исправлено обновлением ПО (заранее перечитал множество release notes и подготовил несколько версий ПО);
- edge/spine коммутаторы порадовали асимметричным прохождением трафика - был открыт кейс производителю, проблема была частично конфигурационная, была найдена и исправлена на текущий момент (но ICMP все так же ходит асимметрично);
- fw по какой-то причине пропускали IP трафик без фрагментации только с сильно меньшим размером пакетов, чем было указано MTU на интерфейсе (считать overhead умеем, ага);
- QSFP28 - отдельно отличился их производитель (3rd party), в один день вышло из строя сразу несколько приемопередатчиков - гарантийный случай, спасло резервирование от двойного отказа, в итоге заменили всю партию приемопередатчиков.
Исходя из этого, могу сказать следующее:
- Что бы тебе не говорил тот или иной производитель, какие-бы заключения самостоятельного тестирования не показывал, всегда могут найтись отклонения в конфигурации, ревизии hardware, в различном software, ошибках в software, в наличии включенных и/или выключенных тех или иных особенностях, которые могут напрямую влиять на исполнение решения поставленной задачи, поэтому, собирать лабораторную среду, даже для синтетических тестов, нужно 1:1, как планируется сделать в продуктивной среде;
- И только после самостоятельного тестирования оборудования на нужных паттернах трафика можно с сомнением сказать, будет ли оно работать или нет, и попросить коллег перепроверить за тобой :) ;
- А с сомнением, все потому, что, синтетические тесты не отменяют продуктивные и в момент времени продуктивный трафик может отличаться от синтетического, что может напрямую повлиять на оборудование и выполнение поставленной задачи;
- Будь готов к проблемам и fallback или изоляции проблемного компонента СПД.
И все же, в итоге, мы получили отказоустойчивую DPI фабрику с возможностью горизонтального масштабирования.
Кроме всего прочего, не стоит забывать, что данная схема имеет место быть и в виртуальной среде.
Благодарности
- Спасибо Анатолию Кушнеру (@orlik) за вычитку и правки;
- Спасибо Дмитрию Владимирову (@DVladimirov) за вычитку и правки;
- Спасибо Ярославу Капсалову за идеи.
Ссылки
Общие подходы к балансировке:
- Доклад Игоря Васильева про балансировку трафика
- Статья про ECMP и балансировку в ДЦ от Марата Сибгатулина
Про hashing:
- Nvidia: Equal Cost Multipath Load Sharing - Hardware ECMP
- Ruckus: Symmetric load balancing
- Consistent Hash Rings Explained Simply
- Google: Maglev: A Fast and Reliable Software Network Load Balancer
Про UCMP:
- Nvidia: Unequal Cost Multipath with BGP Link Bandwidth
- IPSpace: Unequal-Cost Multipath with BGP DMZ Link Bandwidth
- Juniper: Advertising Aggregate Bandwidth Across External BGP Links for Load Balancing Overview
- BGP Link Bandwidth Extended Community