Особенности балансировки в EVPN/VXLAN фабрике
08 Oct 2019 - ipotech
Share on:Особенности балансировки трафика в EVPN/VXLAN фабрике.
Disclaimer: Cтатья не претендует на роль серебряной пули и не описывает все особенности, автор раскрывает лишь собственный опыт.
Причина
В статье 1 приведена бюджетная схема объединения площадок одного провайдера в масштабах города и с использованием DC телекоммуникационного оборудования. Там же упоминаются некоторые неочевидные момент балансировки трафика (фабрика передает MPLS трафик для Back-to-Back 2) включенных маршрутизаторов.
Исходные данные
Arista 7280SR для bridged MPLS имеет в балансировке два сценария:
- Local Bridged: тогда Outer Eth + MPLS;
- VXLAN Decap: тогда Outer IP/UDP + Inner Eth.
Вывод с того же самого коммутатора:
#show load-balance profile
default (global):
Lag Hashing on IP-TCP-UDP headers for IP packets is ON
Lag Hashing on MAC header for IP packets is ON
Full symmetric hashing is OFF
Lag Hashing mode is flow-based
Lag Hash seed is 0 (automatically selected)*
Lag Hash polynomial is 3 (automatically selected)*
Lag Hash key shift is 16 (automatically selected)*
Lag Hashing on ingress interface is ON
Do not adjust the starting header on switchport is OFF
Allowed member selection methods: Multiplication SmoothDistribution
Port-channel load-balancing in egress replication is OFF
MAC hash fields:
Source MAC Address is ON
Destination MAC Address is ON
EtherType is ON
VLAN is ON
MPLS hash fields:
Label is ON
Entropy label is OFF
IPv4 hash fields:
Source IPv4 Address is ON
Destination IPv4 Address is ON
Protocol is ON
Time-To-Live is OFF
IPv6 hash fields:
Source IPv6 Address is ON
Destination IPv6 Address is ON
Flow Label is ON
Hop Limit is OFF
Next Header is ON
L4 hash fields:
Source Port is ON
Destination Port is ON
Packet type MPLS over GRE:
Hashing mode is inner-ip
Первый этап
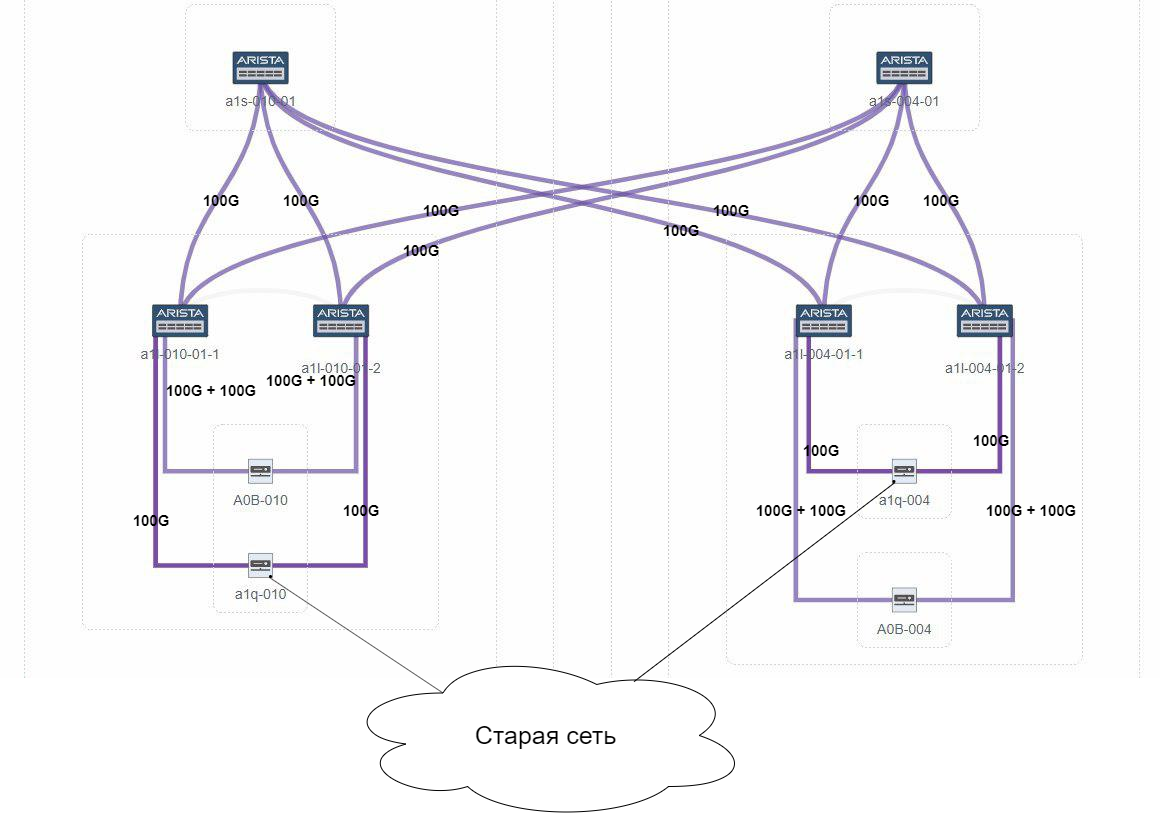
Вооружившись этими знаниями, мы решили стартовать переключение устройств со 100G портами PE-LEAF, а именно их было по 2 в каждый LEAF. Мы настроили между PE и до всех PE в старой сети по 4 UHP LSP (всего около 40 LSP или 40 меток):
 :
:
Паттерн трафика был от A0B в A1q к старой сети, трафик в обратном направлении был невелик.
Точки балансировки:
- Juniper A0B без проблем балансирует по четырём 100G интерфейсам;
- Arista разбирает MPLS заголовок и отправляет трафик:
- Локально (в один порт 100G в сторону A1Q) без проблем;
- В удалённый LEAF. Так как доля трафика между самими A0B невелика, а старая сеть стоит из множества маршрутизаторов, то количество MPLS меток было достаточным для приемлемой, но не идеальной, балансировки на участке LEAF-SPINE-LEAF.
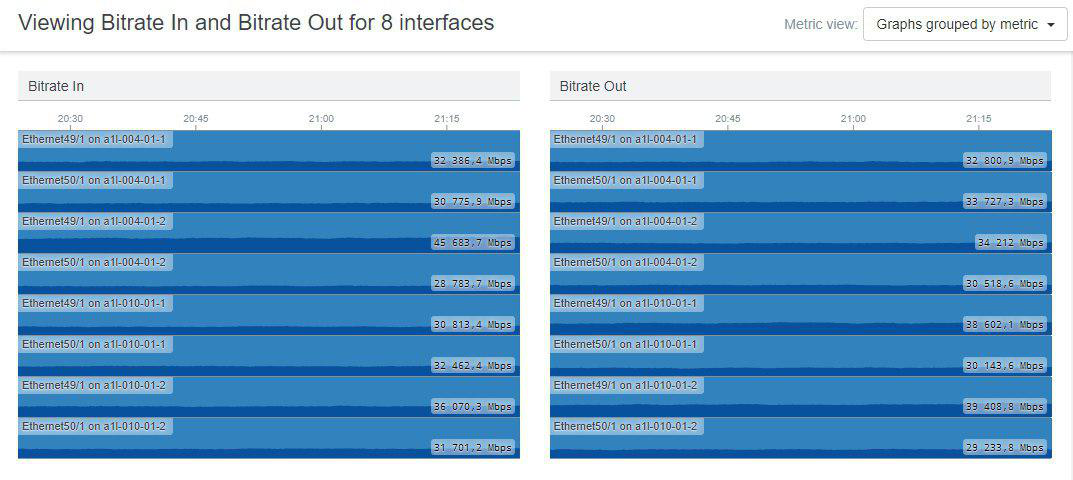
Все выглядело хорошо и мы переключили все “одноногие” (по одному порту в LEAF) PE.
Второй этап
Одним из преимуществ схемы считалась возможность подключать PE к LEAF посредством LAG из 10G портов, которые очень дёшевы - MPC-3D-16XGE-SFPP. Мы воспользовались этим вариантом и схема имела выглядела как:
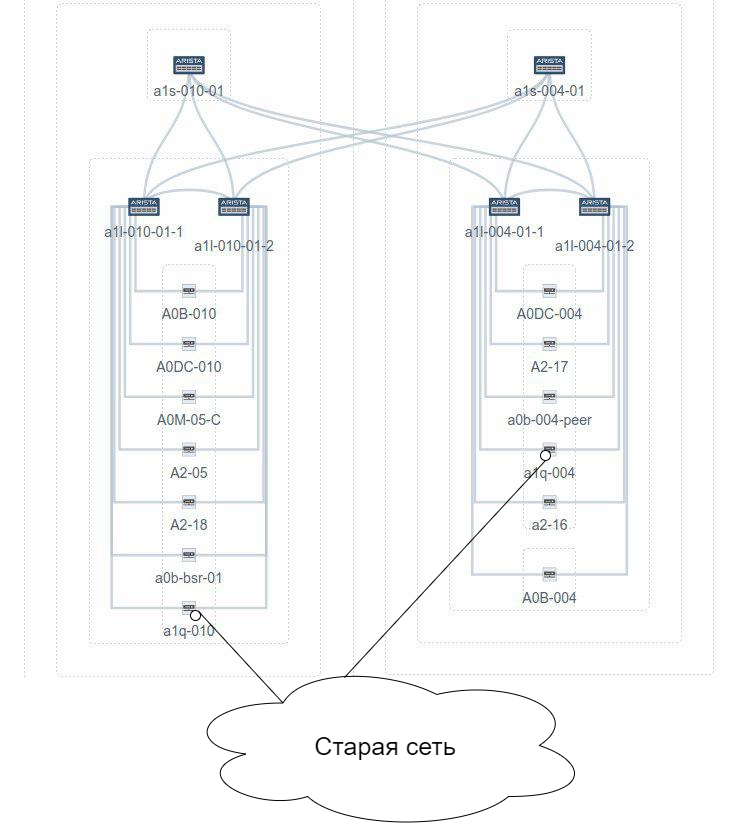
Сфокусируем внимание на подключении А2-17, А2-18 и шаблон их трафика:
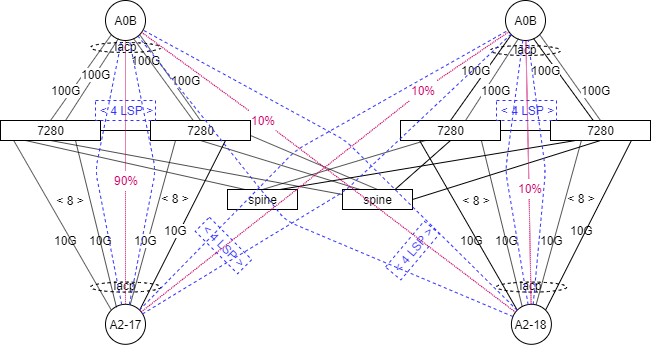
Итого:
- A2-17 и A2-18 включены 16*10G портами в LEAF;
- Между A0B и A2* описано по 4 LSP;
- 90% трафика - это один MPLS L3VPN, одна сервисная метка;
- Трафик идет от A0B к A2, внутри площадки остается до 90% трафика. В обратном направлении трафика мало и мы его не рассматриваем;
- Трафик между А2 присутствует (как и 4 LSP), но его мало и потому мы его тоже не рассматриваем;
- L3 связь между PE одна - это одна пара MAC и IP адресов.
Точки балансировки:
- Juniper A0B без проблем балансирует по четырём 100G интерфейсам;
- Arista разбирает MPLS заголовок и отправляет трафик:
- В сторону удалённого VTEP. Здесь по-прежнему всё хорошо;
- Локально в 8 портов в LACP.
Egress линк LEAF-A2:
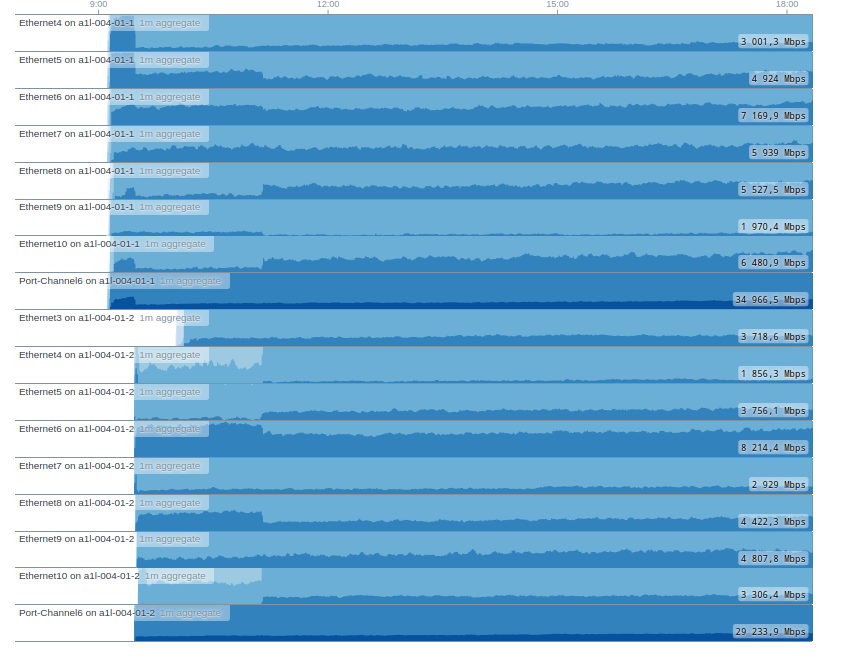
Это удачный скриншот, на некоторых LEAF всё было гораздо хуже. Один 10G интерфес “в полке”, а два загружены лишь на 700Mb/s.
Балансировка Juniper по 8 LSP:
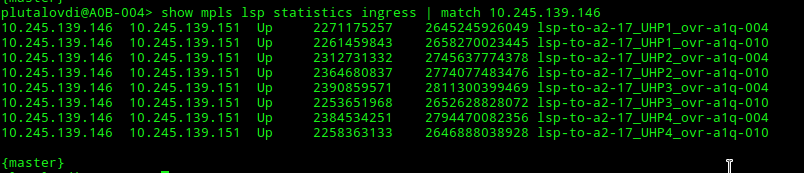
Первое, что мы сделали - увеличили количество LSP до 8, а затем до 16. Ситуация исправлялась, но все равно был перекос в загрузке между интерфейсами. Один интерфейс так и остался “в полке” на часы наибольшей загрузки, но тюнинг большого буфера помог пережить ту ночь. Juniper выделяет метки по порядку, но случайная очистка LSP в качестве попытки улучшить результат hash не помогала.
Опираясь на опыт первого этапа, появилась идея решить проблему путем уменьшения количество портов в LAG группе. Сделать это было возможно так:
- Между двумя PE устанавливалась ещё одна связь в отдельном VLAN;
- В фабрике разные VLAN спускались в разные LAG группы.
В этой схеме Juniper балансировал по двум ECMP IGP маршрутам 16 LSP. Сделав это, мы получили улучшение:

Но результат был далёк от ожидаемого. Можно было довести количество таких интерфейсов до количества портов, то есть до 8, но в этом случае возникают проблемы в эксплуатации.
Решение
Решение удалось найти благодаря активной помощи инженеров Arista и их общению с разработчиками. В базе нашлась статья 3:

Эта “кнопка” сделала сдвиг на один заголовок, а именно на первый Eth, это позволило изучить IP заголовок за MPLS заголовком, а так как там многообразие интернета, то и балансировка стала равномерной.
Ссылки
1. Сервисная архитектура ISP и универсальная транспортная сеть ↩
2. Дампы MPLS пакетов при разных сценариях настройки между Back-to-Back маршрутизаторами Juniper MX ↩
3. VXLAN over MPLS LAG Hashing Optimizations for L2 Ports ↩